Bonjour à tous,
J’ai un problème sur mon serveur hébergé chez OVH.
Debian 8
5 disques de 6To en RAID1 (2 disques)et RAID5 (3 disques) logiciel.
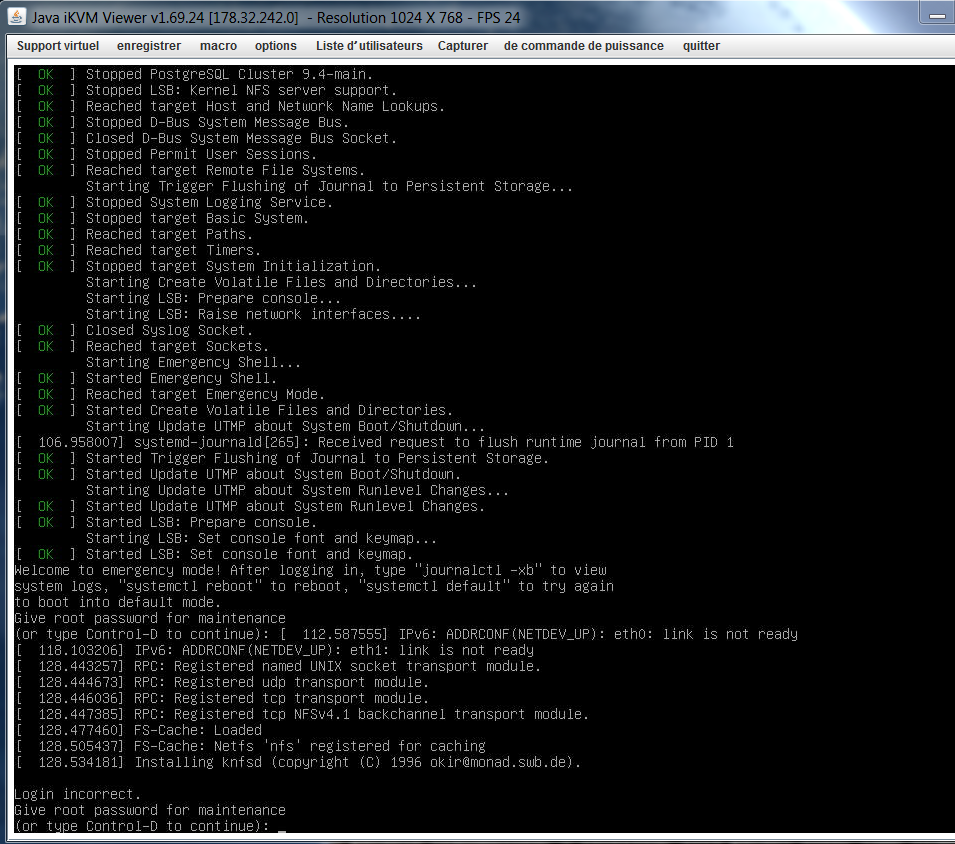
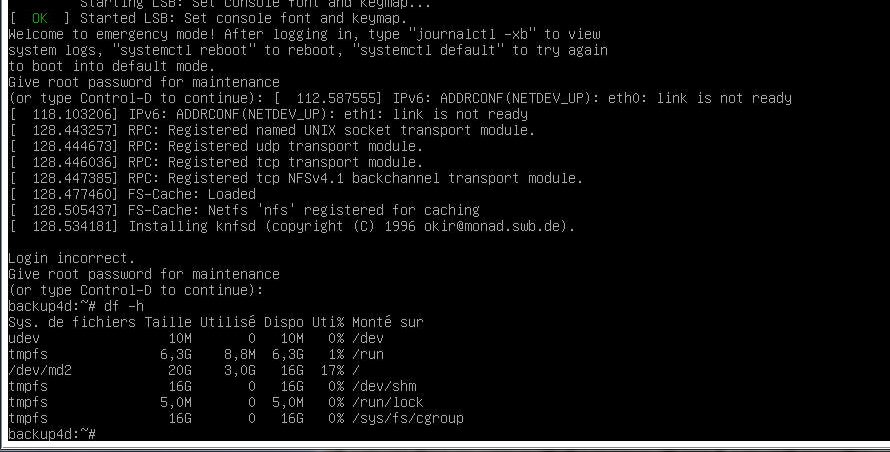
Après l’intervention OVH a redémarré le serveur et depuis je n’arrive pas à démarrer normalement le serveur.
OVH me dit que après redémarrage le système a lancé fsck et tounait en boucle.
J’ai démarré le serveur en mode rescue et j’ai pas grand chose dans les logs.
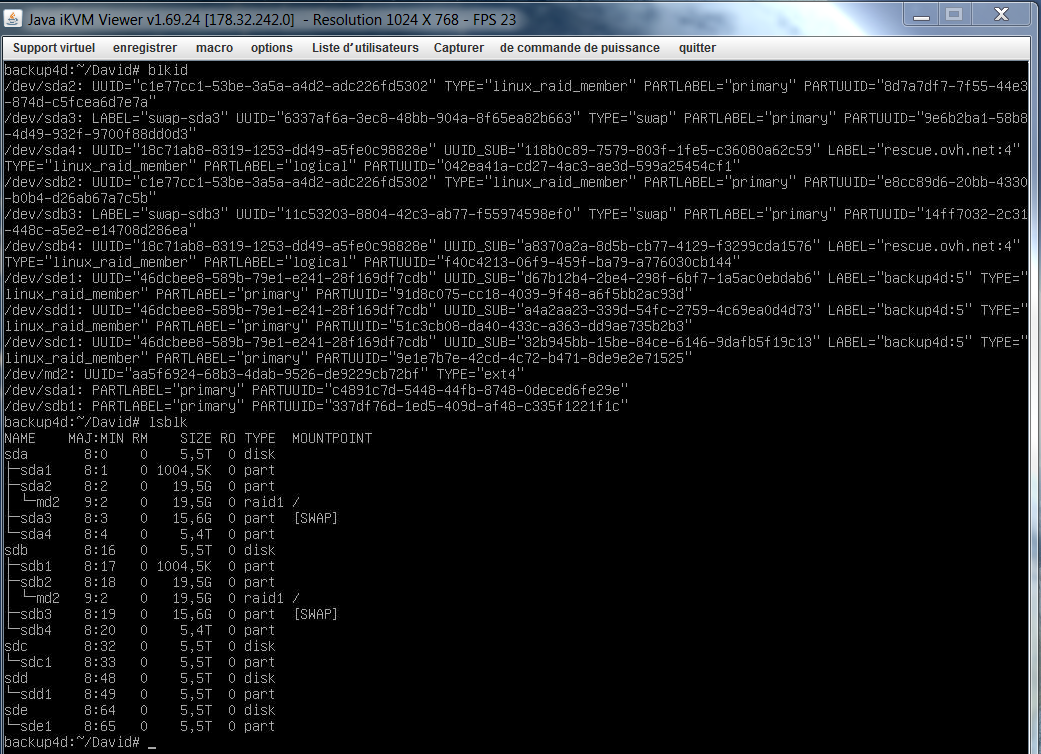
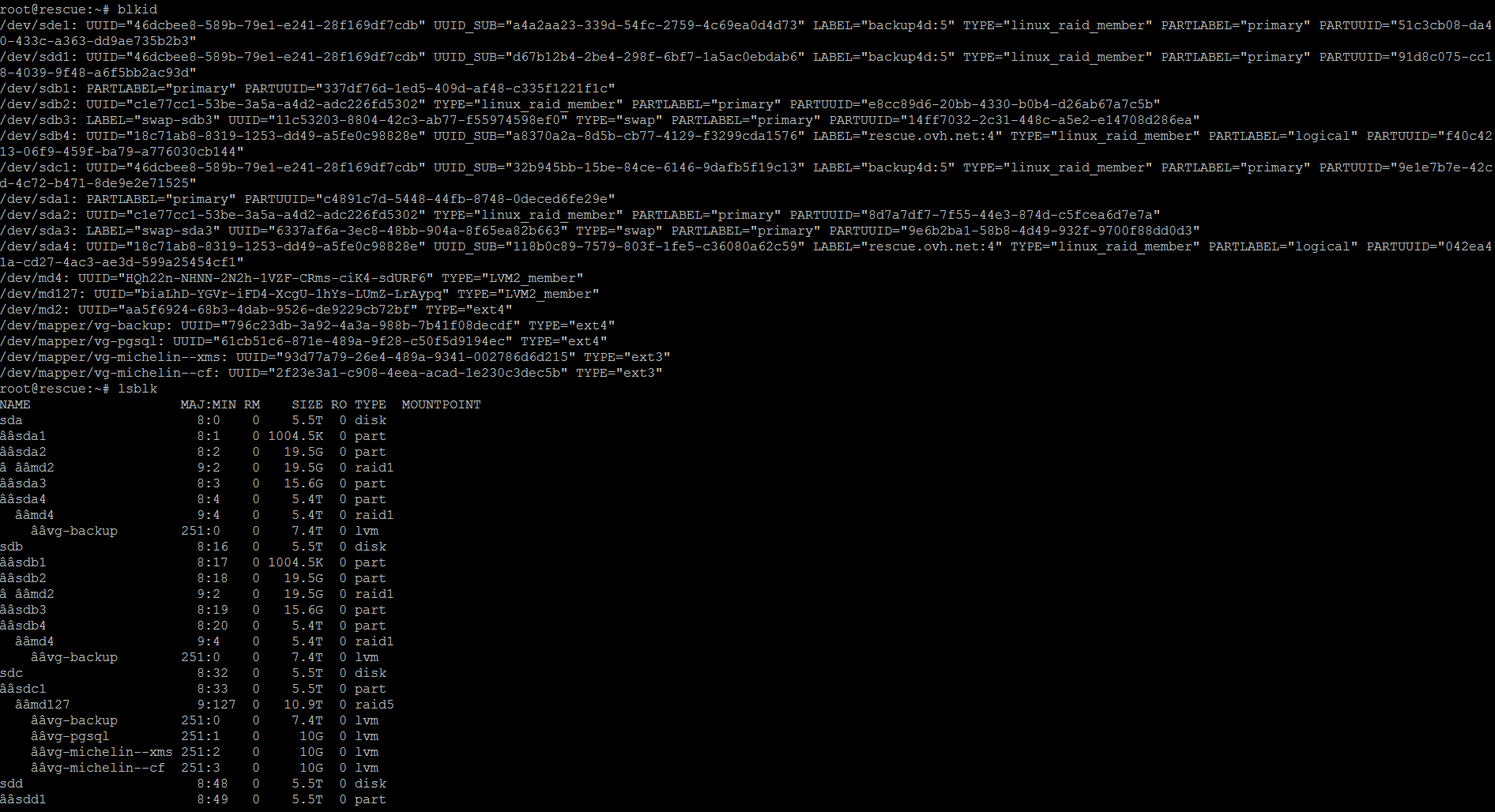
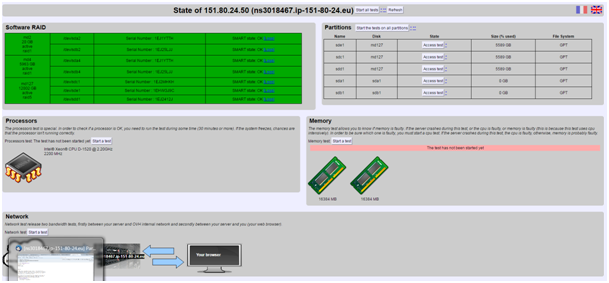
le RAID semble bien fonctionné:
root@rescue:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [multipath] [faulty]
md2 : active raid1 sda2[0] sdb2[1]
20478912 blocks [2/2] [UU]
md4 : active raid1 sda4[0] sdb4[1]
5823522624 blocks super 1.2 [2/2] [UU]
md127 : active raid5 sdc1[0] sde1[3] sdd1[1]
11720779776 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
bitmap: 0/44 pages [0KB], 65536KB chunk
unused devices:
OVH me dit corriger la configuration de votre GRUB afin que votre système démarre normalement.
qqn pourrait m’aider pour corriger/reparer GRUB?
Merci bcp