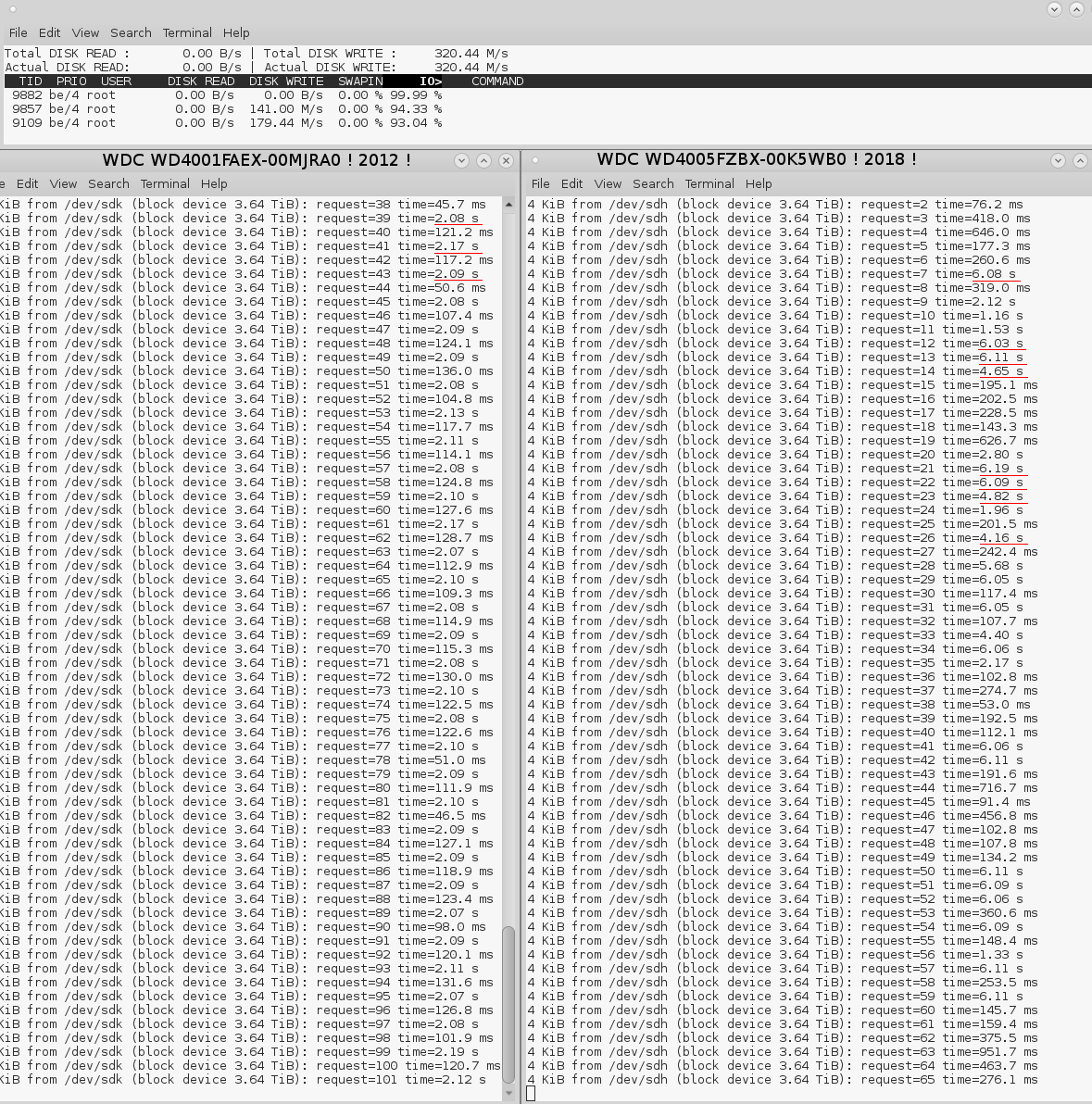
En me connectant au boulot ce soir, j’en ai profité pour faire quelques tests sur notre NAS d’archivage.
Matériel
Réseau
Netgear gamme pro, non administrable et sans jumbo frame
Câbles en catégorie 6
NAS (archives)
FreeNAS 11.2
1 CPU 2C/2T à 2.2 GHz (je n’ai pas pensé à vérifier)
32 Go de mémoire vive
10 Go de swap
Gigabit sur la carte mère
1 clef USB pour le système
8 disques Seagate BarraCuda en RAID-Z2
NB: pas de compression ni dé-duplication
Client (mufasa)
Debian Buster
1 CPU 6C/12T à 3.6-4 GHz
16 Go de mémoire vive
8 Go de swap
Gigabit sur la carte mère
1 SSD pour le système
1 SSD additionnel notamment utilisé pour ces tests
Tests basiques
Dans cette partie, j’écris, je redémarre le NAS et le client, puis je lis.
Locaux
NAS
root@archives[~]# dd if=/dev/zero of=/mnt/achives/local/test1.img bs=1G count=10
10+0 records in
10+0 records out
10737418240 bytes transferred in 22.765970 secs (471643342 bytes/sec)
root@archives[~]# dd if=/mnt/achives/local/test1.img of=/dev/null bs=1G
10+0 records in
10+0 records out
10737418240 bytes transferred in 19.393928 secs (553648456 bytes/sec)
Client
root@mufasa:~# dd if=/dev/zero of=/home/test1.img bs=1G count=10
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 16,2849 s, 659 MB/s
root@mufasa:~# dd if=/home/test1.img of=/dev/null bs=1G
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 4,10749 s, 2,6 GB/s
NFS
root@mufasa:~# dd if=/dev/zero of=/mnt/achives/nfs/test1.img bs=1G count=10
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 163,775 s, 65,6 MB/s
root@mufasa:~# dd if=/mnt/achives/nfs/test1.img of=/dev/null bs=1G
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 92,4577 s, 116 MB/s
CIFS (cifs-utils)
root@mufasa:~# dd if=/dev/zero of=/mnt/achives/cifs/test1.img bs=1G count=10
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 92,7434 s, 116 MB/s
root@mufasa:~# dd if=/mnt/achives/cifs/test1.img of=/dev/null bs=1G
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 91,7545 s, 117 MB/s
Tests parallèles
Dans cette partie, après avoir redémarrer le NAS et le client, j’écris un nouveau fichier et lis le précédent.
Locaux
NAS
root@archives[~]# dd if=/dev/zero of=/mnt/achives/local/test2.img bs=1G count=10
10+0 records in
10+0 records out
10737418240 bytes transferred in 27.070581 secs (396645288 bytes/sec)
root@archives[~]# dd if=/mnt/achives/local/test1.img of=/dev/null bs=1G
10+0 records in
10+0 records out
10737418240 bytes transferred in 22.190839 secs (483867154 bytes/sec)
Client
root@mufasa:~# dd if=/dev/zero of=/home/test2.img bs=1G count=10
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 23,7924 s, 451 MB/s
root@mufasa:~# dd if=/home/test1.img of=/dev/null bs=1G
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 25,7933 s, 416 MB/s
NFS
root@mufasa:~# dd if=/dev/zero of=/mnt/achives/nfs/test2.img bs=1G count=10
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 143,443 s, 74,9 MB/s
root@mufasa:~# dd if=/mnt/achives/nfs/test1.img of=/dev/null bs=1G
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 205,801 s, 52,2 MB/s
CIFS (cifs-utils)
root@mufasa:~# dd if=/dev/zero of=/mnt/achives/cifs/test2.img bs=1G count=10
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 94,8191 s, 113 MB/s
root@mufasa:~# dd if=/mnt/achives/cifs/test1.img of=/dev/null bs=1G
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 161,048 s, 66,7 MB/s
Pas inutiles ces tests, ça m’a permis de voir que sur ce serveur, le NFS est moins performant 
En cherchant pourquoi NFS était si lent sur ce serveur, je suis tombé sur l’option sync de ZFS, lorsqu’elle est désactivée:
Tests basiques
root@mufasa:~# dd if=/dev/zero of=/mnt/achives/nfs/test1.img bs=1G count=10
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 93,1501 s, 115 MB/s
root@mufasa:~# dd if=/mnt/achives/nfs/test1.img of=/dev/null bs=1G
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 81,7583 s, 131 MB/s
Tests parallèles
root@mufasa:~# dd if=/dev/zero of=/mnt/achives/nfs/test2.img bs=1G count=10
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 95,3334 s, 113 MB/s
root@mufasa:~# dd if=/mnt/achives/nfs/test1.img of=/dev/null bs=1G
10+0 enregistrements lus
10+0 enregistrements écrits
10737418240 octets (11 GB, 10 GiB) copiés, 130,609 s, 82,2 MB/s
Je pense que la mise en cache est paramétrable, mais dit toi que rien n’est plus rapide que la RAM.
C’est vrai que c’est light, mais c’est surtout propre. Je hais les droits Windows et malheureusement, le NAS des fichiers utilisateurs de mon boulot, est en Windows…
Tu as essayé avec du swap ou pas?