
J’ai chez moi depuis plus de six ans un serveur NTP (qui est d’ailleurs dans le pool NTP). Ce serveur marche fort bien mais a un bug bizarre depuis le passage à squeeze (sans certitude, je ne me souviens pas de ce bug au début mais bon).
Les faits:
Toutes les 2^22 secondes soit en gros 1 mois 20 jours, le serveur, prend 89,06s ( 89.061056 89.062137 89.060370 89.061128 89.061191 89.061366 89.060620 et 89.060533) d’avance (et est ejecté du pool donc). Les bugs se sont produit à ces dates (et peut être avant):
12/08/2014 13:44:02
30/09/2014 02:56:06
17/11/2014 15:02:38
05/01/2015 04:14:12
22/02/2015 17:21:55
12/04/2015 07:30:46
30/05/2015 20:40:21
18/07/2015 09:48:24
Le prochain est donc prévu le 4 septembre vers 22h53.
Le serveur est un stratum 2 et ça n’est pas du semble-t-il à une dérive du serveur de stratum 1 (un décalage à ce point n’est de toute façon pas possible).
Le noyau est un 2.6.32-5-686 et la ntp est 1:4.2.6.p2+dfsg-1+deb6u3
Sur un autre serveur ntp, lui aussi dans le pool, lui aussi squeeze, avec la même version de ntp mais le noyau de lenny 2.6.26-2-686, il n’y a pas ce bug.
Je pense plutôt à un souci matériel, j’ai le souvenir d’un plantage du module rtc de temps à autre avant de changer de noyau. La machine a été reboutée aux dates suivantes
francois@cerbere:/var/log$ ls -altr dmesg*
-rw-r----- 1 root adm 6847 17 avril 2012 dmesg.4.gz
-rw-r----- 1 root adm 6456 20 mai 2013 dmesg.3.gz
-rw-r----- 1 root adm 6494 19 d�c. 2013 dmesg.2.gz
-rw-r----- 1 root adm 7935 7 f�vr. 2014 dmesg.1.gz
-rw-r----- 1 root adm 22567 10 avril 2014 dmesg.0
-rw-r----- 1 root adm 23616 7 mai 2014 dmesg
le passage en squeeze ayant été fait le 7 février 2014.
C’est un FitPC installé en 2008 (cf fit-pc-des-experiences-t14156-25.html ) qui marche de façon continuelle (là son uptime est de 11:42:58 up 437 days, 3 min, 2 users, load average: 0.13, 0.29, 0.25).
Le bug en lui même ne me gêne pas, je vais faire un «at» régulier qui relancera le démon ntp tous les 2^22 secondes mais j’aimerais avoir une explication notamment savoir pourquoi 89,06s.
Si quelqu’un a une idée. Je poste aussi sur la DUF.
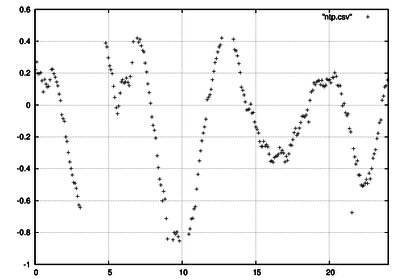 ), l’étonnant est ce décrochement brutal qui semble soit un pbm de retenue, soit peut être un calage soudain sur l’heure hardware si celle ci n’est pas ajustée. Mais pendant tout le temps le serveur était parfaitement ajusté avec un écart d’au maximum 5ms[quote]
), l’étonnant est ce décrochement brutal qui semble soit un pbm de retenue, soit peut être un calage soudain sur l’heure hardware si celle ci n’est pas ajustée. Mais pendant tout le temps le serveur était parfaitement ajusté avec un écart d’au maximum 5ms[quote]