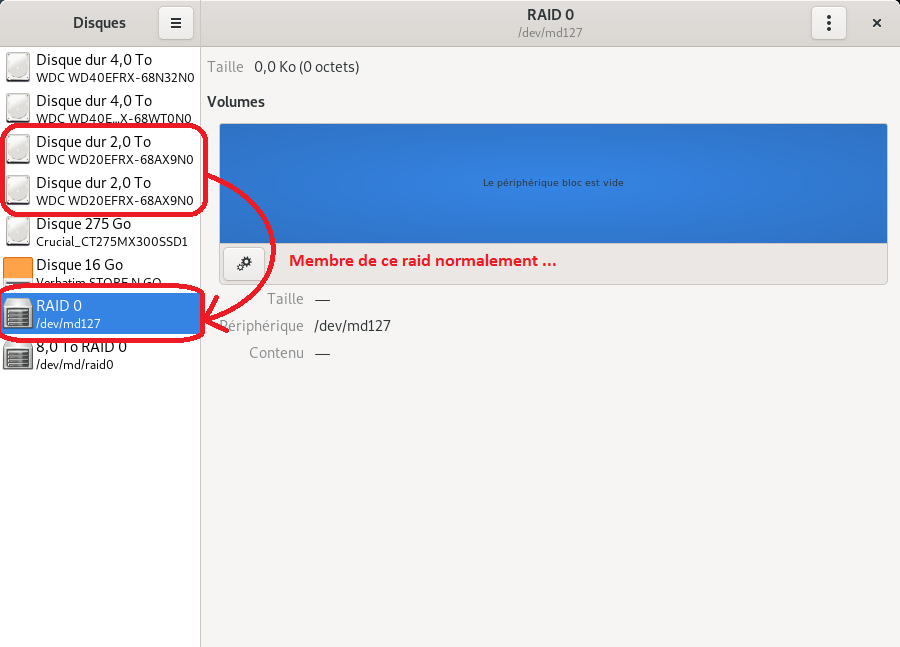
ARGGG, y’a un truc aussi qui m’énerve, depuis un moment les commandes de bases reconnu normalement à la saisie dans un terminal ne fonctionne plus.
Je suis OBLIGÉ de me rendre ou la commande se trouve et faire un ./ devant.
Tu aurais une idée aussi ?
La pour te faire fdisk, je suis aller dans /usr/sbin/
et ./fdisk -l /dev/sdc
grrrr …
Disque /dev/sdc : 1,82 TiB, 2000397852160 octets, 3907027055 secteurs
Modèle de disque : WDC WD20EFRX-68A
Unités : secteur de 1 × 512 = 512 octets
Taille de secteur (logique / physique) : 512 octets / 4096 octets
taille d'E/S (minimale / optimale) : 4096 octets / 4096 octets
Type d'étiquette de disque : gpt
Identifiant de disque : 7E0DF9FD-9728-40AA-B490-C461E68448B6
Périphérique Début Fin Secteurs Taille Type
/dev/sdc1 2048 3907026943 3907024896 1,8T Système de fichiers Linux
./fdisk -l /dev/sdd :
Disque /dev/sdd : 1,82 TiB, 2000398934016 octets, 3907029168 secteurs
Modèle de disque : WDC WD20EFRX-68A
Unités : secteur de 1 × 512 = 512 octets
Taille de secteur (logique / physique) : 512 octets / 4096 octets
taille d'E/S (minimale / optimale) : 4096 octets / 4096 octets
Type d'étiquette de disque : gpt
Identifiant de disque : 90CCDA62-456F-43E6-9C99-03E621EB3ECC
Périphérique Début Fin Secteurs Taille Type
/dev/sdd1 2048 3907028991 3907026944 1,8T Système de fichiers Linux
root@PiBox:/usr/sbin# ./fdisk -l /dev/sdd
Disque /dev/sdd : 1,82 TiB, 2000398934016 octets, 3907029168 secteurs
Modèle de disque : WDC WD20EFRX-68A
Unités : secteur de 1 × 512 = 512 octets
Taille de secteur (logique / physique) : 512 octets / 4096 octets
taille d'E/S (minimale / optimale) : 4096 octets / 4096 octets
Type d'étiquette de disque : gpt
Identifiant de disque : 90CCDA62-456F-43E6-9C99-03E621EB3ECC
Périphérique Début Fin Secteurs Taille Type
/dev/sdd1 2048 3907028991 3907026944 1,8T Système de fichiers Linux
enfin mdadm --examine /dev/sdc1 /dev/sdd1
/dev/sdc1 2048 3907026943 3907024896 1,8T Système de fichiers Linux
root@PiBox:/usr/sbin# ./mdadm --examine /dev/sdc1 /dev/sdd1
/dev/sdc1:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : 4136c8cb:75030801:1e330467:5ff97e85
Name : PiBox:raidGA (local to host PiBox)
Creation Time : Wed Oct 27 21:41:58 2021
Raid Level : raid0
Raid Devices : 2
Avail Dev Size : 3906760704 (1862.89 GiB 2000.26 GB)
Data Offset : 264192 sectors
Super Offset : 8 sectors
Unused Space : before=264112 sectors, after=0 sectors
State : clean
Device UUID : 0baf1b8f:4a87d06e:1b87313a:01aff774
Update Time : Wed Oct 27 21:41:58 2021
Bad Block Log : 512 entries available at offset 8 sectors
Checksum : cd6cfd76 - correct
Events : 0
Chunk Size : 512K
Device Role : Active device 0
Array State : AA ('A' == active, '.' == missing, 'R' == replacing)
/dev/sdd1:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : 4136c8cb:75030801:1e330467:5ff97e85
Name : PiBox:raidGA (local to host PiBox)
Creation Time : Wed Oct 27 21:41:58 2021
Raid Level : raid0
Raid Devices : 2
Avail Dev Size : 3906762752 (1862.89 GiB 2000.26 GB)
Data Offset : 264192 sectors
Super Offset : 8 sectors
Unused Space : before=264112 sectors, after=0 sectors
State : clean
Device UUID : 9bc8e97d:1a2b31f5:f8b3f3c8:188a4815
Update Time : Wed Oct 27 21:41:58 2021
Bad Block Log : 512 entries available at offset 8 sectors
Checksum : 71aecacc - correct
Events : 0
Chunk Size : 512K
Device Role : Active device 1
Array State : AA ('A' == active, '.' == missing, 'R' == replacing)