Yahallo x)
On sait qu’avec DRBD il est possible de faire du “raid 1 sur réseau”.
Mais, existe-il une méthode, technique, logiciel permettant de faire du RAID 5-6-… en réseau ?
Merci d’avance 

Yahallo x)
On sait qu’avec DRBD il est possible de faire du “raid 1 sur réseau”.
Mais, existe-il une méthode, technique, logiciel permettant de faire du RAID 5-6-… en réseau ?
Merci d’avance
Du moment où tu peux accéder à des périphériques de mémoire de masse par le réseau, comme par exemple avec nbd (Network block device) rien ne t’empêche de les organiser comme bon te semble.
Okay, thanks !
Et ceci aussi :
Je comprends pas tout à fait la différence entre ces deux termes :
Block storage et Object Storage
Je dirais qu’il s’agit de différents niveaux d’abstraction :
Un Object storage permet de manipuler des données sous forme d’objets.
Dans un “Block Storage” les données sont organisées en “blocs physiques”, secteurs consécutifs de 512 (ou 2048 octets, ou autre).
Ce sont ces blocs qui vont êtres utilisés par le “Files system” pour accéder aux fichiers qui présentent les données classées de façon hiérarchique, et c’est peut-être dans la hiérarchie de ces différents fichiers que sont stockées les caractéristiques des objets accessibles par l’“Object Storage”.
Je ne suis pas sûr de l’avoir très bien expliqué, mais il y a des personnes bien plus compétentes que moi
qui passeront sans doute lire ce fil et qui pourront te l’expliquer beaucoup mieux que moi.
Si j’ai compris, merci !
L’object storage assure mieux les compatibilités entre les systèmes de fichiers par le fait.
Mais je vois pas davantage concernant le block storage…
Rien n’empêche de monter un RAID5 dans un LVM, qui sera répliqué sur deux ou trois machines via DRDB.
Tout comme de monté des grappes raid 5 ou 6 avec du glusterfs répliqué sur autant de nœud qu’il est nécessaire.
Fais un RAID 5 répliqué en DRDB revient à faire du RAID 1 par réseau
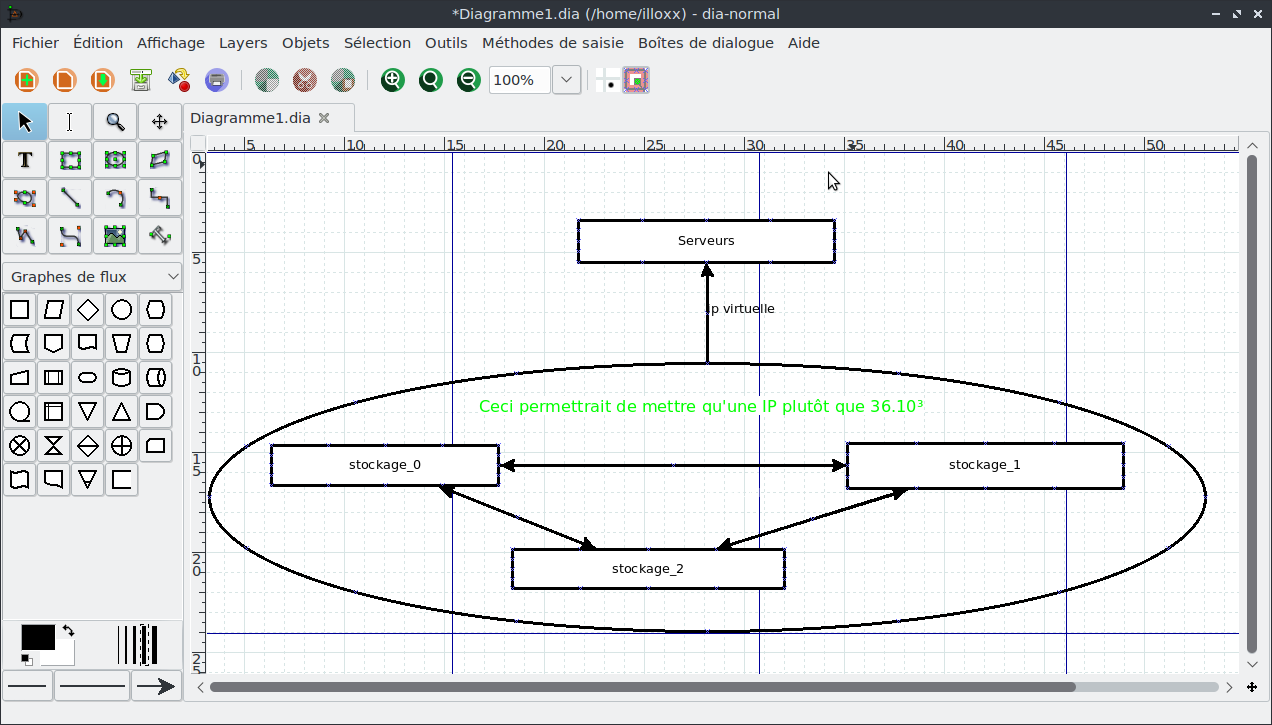
Le but n’est pas de répliquer, mais d’avoir une ip virtuelle pour plusieurs serveurs de stockages. x)
C’est extrêmement fastidieux d’avoir X serveurs de stockage… Il est plus aisé à travailler avec un gros disque dur un réseau, plutôt que pleins de petits (vous voyez l’analogie ?).
Dans ce cas là tente une reconstruction de ton volume raid par le réseau et tu comprendra pourquoi je parle de travailler plus efficacement par grappes de stockage répliquées 
Si le but est de permettre l’exploitation de donnée de façon intensive alors DRDB sur deux ou trois nœuds est le plus performant et le plus simple à entretenir.
Si maintenant c’est purement du stockage, voir du stockage à froid alors Glusterfs est ton ami et te voudra que tu bien, il te permettra de répartir efficacement tes données sur plusieurs machines te permettant une forte résilience à la panne sans t’obliger à faire des pieds et des mains pour la maintenance.
Le fait de vouloir faire du raid1 par le réseau et sympathique, mais le jour ou tu doit reconstruire le volume …
Autant appeler un chat un chat, ce que tu cherche finalement c’est un SAN ou un NAS, encore une fois selon tes besoins.
Yep, du SAN.
Mais je me demande si on peut faire toute une grappe de iscsi target… (je débute dans le cloud computing côté stockage)
Si tu compte exploiter du iscsi pour du cloud computing, et que tu débute reste le plus simple possible.
à la maison je travail pour le stockage à froid sur du freenas, et pour le stockage à chaud j’ai déjà testé GlusterFS et suis resté pas mal de temps sur drdb avant de partir sur du CEPH.
Mais c’est très personnel.
Actuellement je suis toujours ne pleins démontages de mon Ancien Openstack et en cours de remodelage de mon cloud personnel pour abaisser le coût de la facture électrique.
Effectivement, il y a Ceph… Mais c’est complexe.
J’ai lu les docs en long en large en travers, mais bon, il me faut la pratique.
Je compte me servir d’openSUSE avec Yast pour le iscsi…
Meilleure taille : https://www.debian-fr.org/uploads/default/original/2X/8/8eca13820809fa58ab5b0bc893cc33406f1cb0b4.png
nbd, pas ndb. (Pour l’indexation et la recherche)
NDB, c’est pour la navigation aérienne.
Veuillez regarder le schéma ci-dessus, j’ai édité 
Pour me permettre de comprendre, stockage 0 ,1 , 2 sont trois grappes de disques sur trois machines différentes ? ou dans une me^me machines ?Comme déjà dit plus haut tout dépendra de la résilience et du pognon à mettre dans ton histoire et des moyens technique à mettre en œuvre pour maintenir le bouzin.
GlusterFS n’est pas tip top sur les anciennes versions pour du gros volume et de la performance.
DRDB très bien du moment que l’on reste sur un max de trois machines, couplé à corosync/pacemaker tu aura une gestion très fine de ce que tu veux gérer via une IP virtuelle.
CephFS bien mais faut pouvoir le gérer.
Pour du stockage à froid je suis on ne peut plus content de Freenas qui me procure tout ce dont j’ai besoin avec une gestion de snapshot et des mécanisme puissant de gestion d’incident, pas encore utilisé le DEDUP (pas asssez de ram pour ça ).
Pour tous ce qui est mysql je ne saurai trop te consiller de partir direct vers du galera ou du percona (j’ai un penchant pour le premier).
Dans le cas de postgresql c’est un poil plus barbus pour gérer du actif/actif sans ennui de lock intempestif.
Après pour du home made, openfiler est bien pour commencer à jouer avec de la LUN et de l’ISCSI.
J’avoue que Ceph me séduit… Mais reste complexe… 
Pour MySQL, merci du conseil !
Oui, effectivement, (j’avais ajouté la parenthèse Network block device)
Je corrige mon précédent message.
Merci de l’avoir signalé.