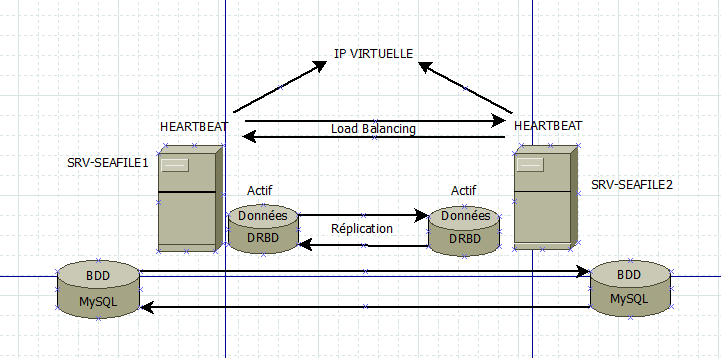
Pour les ‘Single Point Of Failure’, il faut veiller a ce que les machines soient sur des alimentations redondées et surtout branchées sur deux alimentations différentes (avec des onduleur serait un plus).
La partie Switch doit elle aussi être redondé et pas brancher sur la même alimentation électrique, sinon concernant le schéma c’est d’après moi correcte.
Attention le drdb doit-être monté avant tout dépose de donnée, et à mon humble avis les fichiers de conf de seafile et la/les bases de données peuvent être mise dessus, sinon il faudra couplé une synchronisation via rsync pour les fichiers de confs et autres de seafile
Un ‘PRA’ ne serait pas non plus une chose inutile selon l’importance que tu donne à ton bouzin (un troisième machine avec un mysql-replicator serait idéale pour être maintenu sans soucis et reprendre en cas de crash monstrueux l’activité le temps de remonté l’ensemble de ta solution from scratch avec des backups.

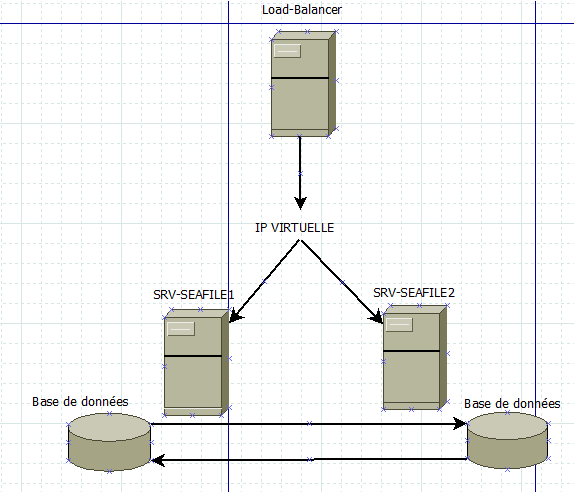

 qui vont grogner en attendant que tu puisses rétablir l’accès.
qui vont grogner en attendant que tu puisses rétablir l’accès.
 )
)