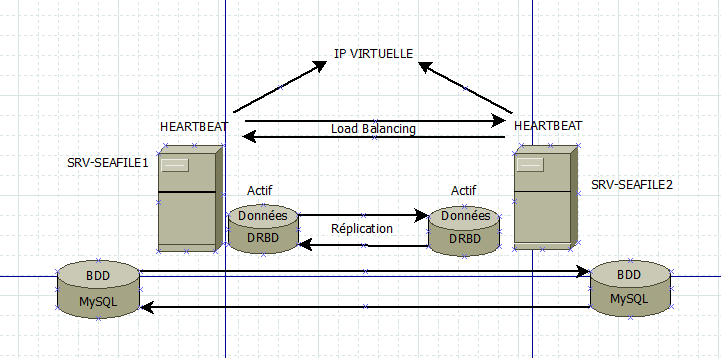
Heartbeat peu s’accommoder de gérer la partie web comme la partie bdd.
De manière personnel je préfère le couple corosync et pacemaker plutôt que hartbeat et mon mais c’est affaire de goût.
La réplication mysql peu s’effectuer par le biais de mysql replicator ou alors par un mécanisme plus
velu à base de DRBD.
Exemple trouvé sur le web rapidement (pas à jour mais c’est pas bien grave il faudra simplement adapter) :
http://denisrosenkranz.com/tuto-ha-un-cluster-drbdmysql-avec-heartbeat-sur-debian-7/
Etg en exmple pour corosyncpacemaker : https://www.linux-dev.org/2016/03/debian-jessie-8-3-short-howto-for-corosyncpacemaker-activepassive-cluster-with-two-nodes-and-drbdlvm/