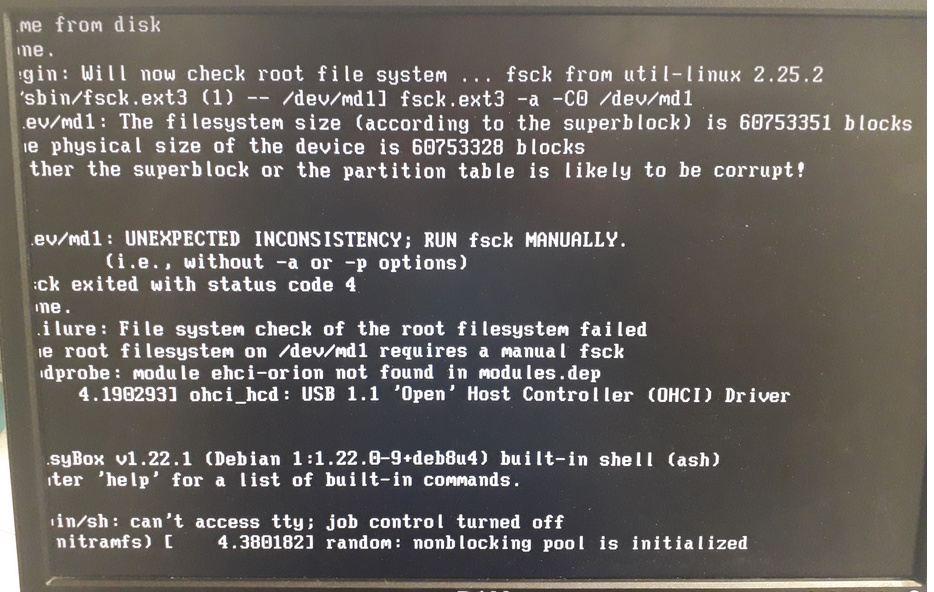
Ah, oui, ça me rappelle quelque chose. Une différence est que le noyau 3.2 utilise des pilotes distincts pour les systèmes de fichiers ext2, ext3 et ext4 alors que le noyau 3.16 utilise le même pilote ext4 pour tous les systèmes de fichiers ext*, ce qui permet de bénéficier de certaines de ses fonctionnalités même en ext2 et ext3. Or le pilote ext4 est plus strict sur la cohérence entre la taille déclarée par le système de fichiers (visible avec tune2fs -l /dev/md1) et la taille du volume qui le contient (visible dans /proc/partitions ou /proc/mdstat). Evidemment, la taille déclarée ne doit pas être plus grande que celle du contenant.
Ici c’est le programme de vérification/réparation fsck.ext3 (e2fsck) exécuté par l’initramfs du noyau 3.16 qui détecte l’incohérence, avant le montage de la racine par le noyau. Au passage, il ne permet pas de corriger ce type de problème. Je soupçonne que le problème ne se produit pas avec le noyau 3.2 parce que son initramfs généré avec les outils de Wheezy ne lance pas fsck.
Les fois où j’ai vu ce problème avec du RAID, il était causé par une mauvaise mise en place du RAID sur une partition initialement formatée sans RAID, la taille qui manque correspondant à l’espace occupé par les méta-données du RAID.