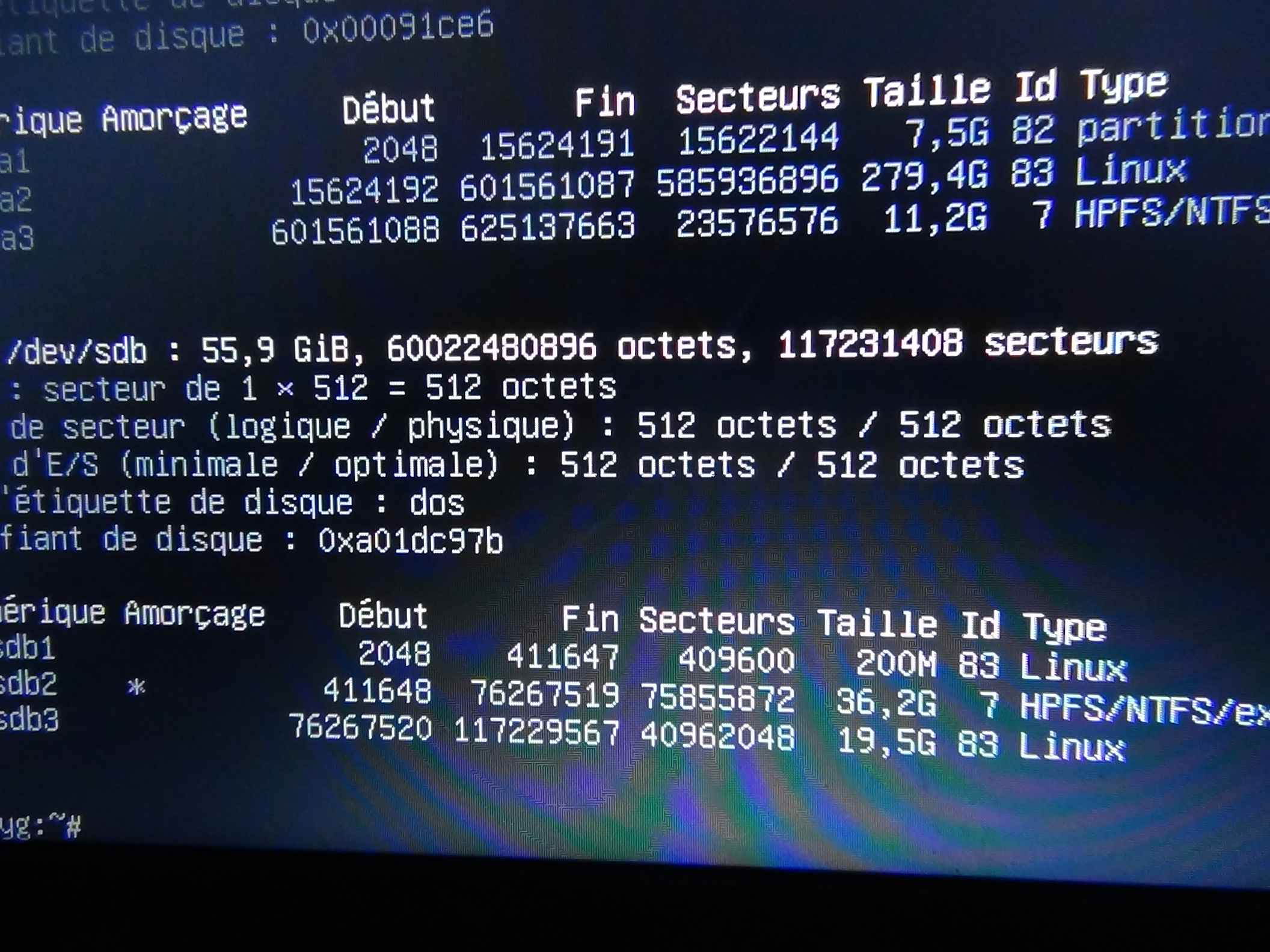
Quelques recherches m’amenent ici
https://www.smartmontools.org/wiki/FAQ#ATAdriveisfailingself-testsbutSMARThealthstatusisPASSED.Whatsgoingon
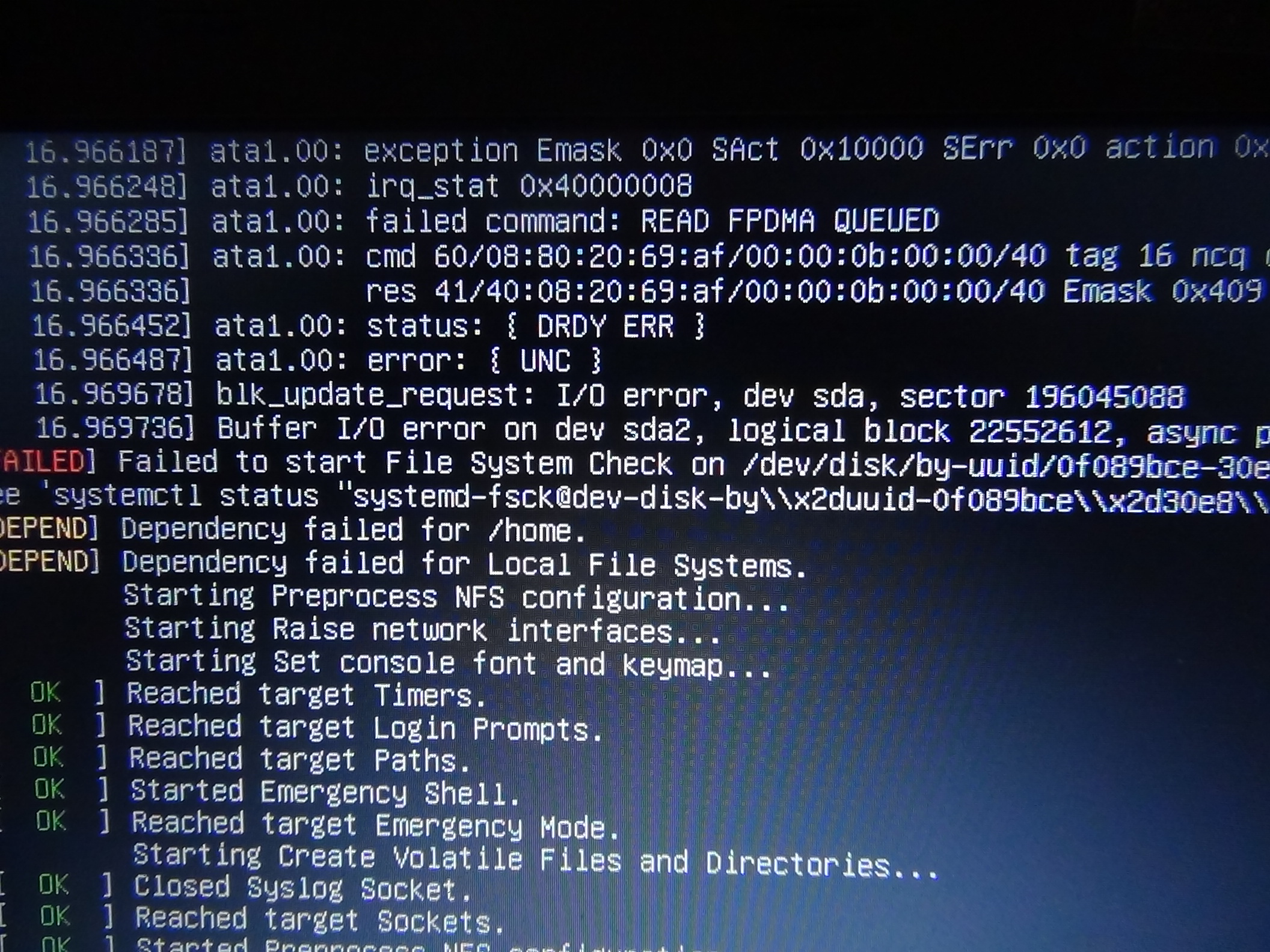
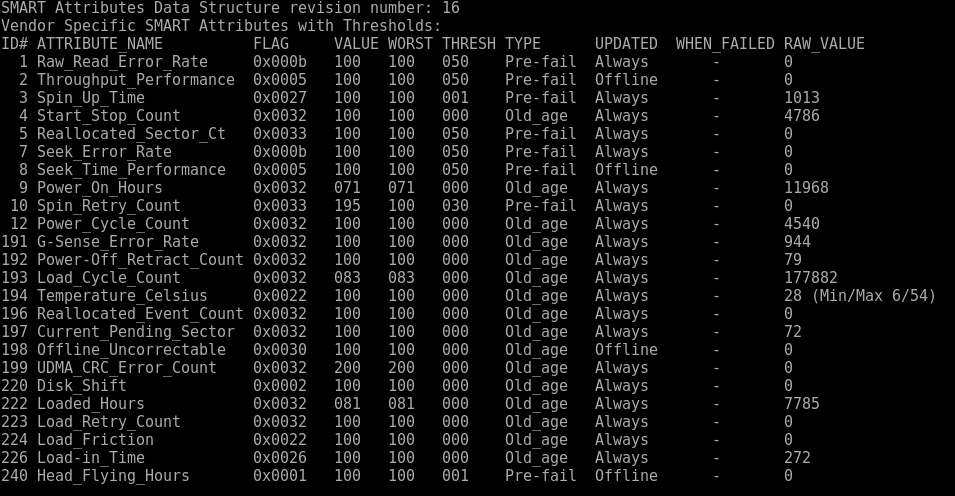
If the drive fails a self-test, but still has ‘PASSED’ SMART health status, this usually means that there is a corrupted (uncorrectable=UNC) sector on the disk. This means that the ECC data stored at that sector is not consistent with the user data stored at that sector, and an attempt to read the sector fails with a UNC error. This can be a one-time transient effect: a sudden power failure while the disk was writing to the sector corrupted the ECC code or data, but the sector could correctly store new data. Or it can be a permanent effect: the magnetic media has been damaged by a bit of dust, and the sector could not correctly store new data.
If the disk can read the sector of data a single time, and the damage is permanent, not transient, then the disk firmware will mark the sector as ‘bad’ and allocate a spare sector to replace it. But if the disk can’t read the sector even once, then it won’t reallocate the sector, in hopes of being able, at some time in the future, to read the data from it. A write to an unreadable (corrupted) sector will fix the problem. If the damage is transient, then new consistent data will be written to the sector. If the damange is permanent, then the write will force sector reallocation. Please see Bad block HOWTO for instructions about how to force this sector to reallocate (Linux only).
Traduction Google
Si le disque échoue à un autotest, mais a toujours l’état d’intégrité SMART ‘PASSED’, cela signifie généralement qu’il y a un secteur corrompu (uncorrectable = UNC) sur le disque. Cela signifie que les données ECC stockées sur ce secteur ne sont pas cohérentes avec les données utilisateur stockées dans ce secteur, et qu’une tentative de lecture du secteur échoue avec une erreur UNC. Cela peut être un effet transitoire ponctuel: une panne de courant soudaine pendant que le disque écrivait dans le secteur corrompait le code ou les données ECC, mais le secteur pouvait stocker correctement de nouvelles données. Ou cela peut être un effet permanent: le support magnétique a été endommagé par un peu de poussière et le secteur n’a pas pu stocker correctement de nouvelles données.
Si le disque peut lire le secteur de données une seule fois, et que les dommages sont permanents et non transitoires, alors le micrologiciel du disque indiquera que le secteur est ‘mauvais’ et allouera un secteur de réserve pour le remplacer. Mais si le disque ne peut pas lire le secteur une seule fois, il ne réaffectera pas le secteur, dans l’espoir de pouvoir, à un moment donné dans le futur, en lire les données. Une écriture dans un secteur illisible (corrompu) résoudra le problème. Si les dommages sont transitoires, de nouvelles données cohérentes seront écrites dans le secteur. Si le damange est permanent, alors l’écriture forcera la réallocation de secteur. Reportez-vous à Bad block HOWTO pour obtenir des instructions sur la façon de forcer la réallocation de ce secteur (Linux uniquement).
Et la démarche pas à pas pour réparer:
https://www.smartmontools.org/wiki/BadBlockHowto